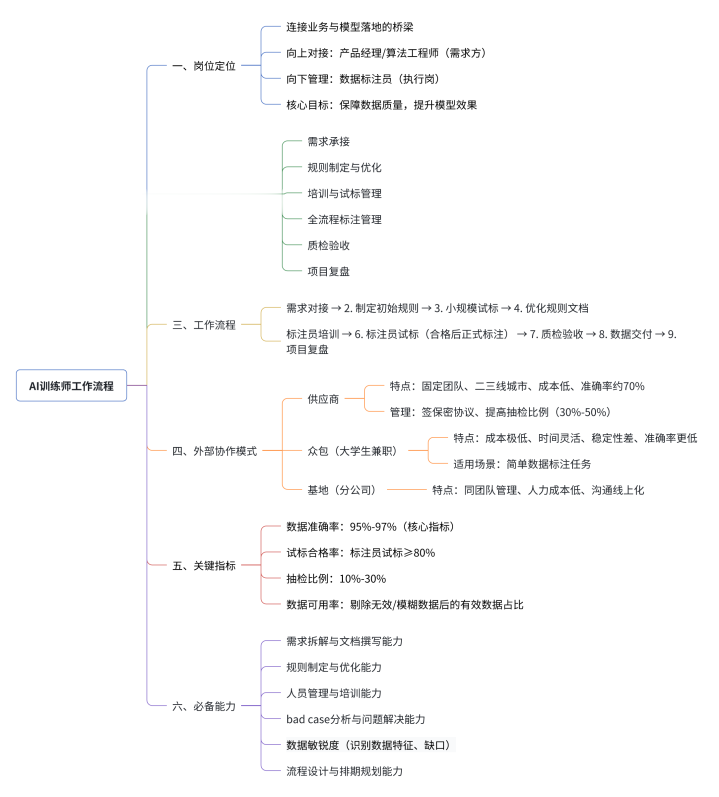
拆解AI训练师核心工作: 需求承接、规则制定、质检验收全流程(含多模态模型认知)
AI训练师正成为AI项目落地的关键角色。本文系统拆解从大语言模型原理到项目全流程执行的实战方法,涵盖需求分析、数据标注、团队管理等核心环节,并提供汽车厂商标注案例的完整方案模板。无论是新手入门还是团队标准化建设,都能从中获得可直接落地的操作指南。

本文基于核心知识框架,系统梳理AI模型基础概念、AI训练师核心职责、项目全流程执行规范及外部资源协同策略,为AI项目团队提供标准化、可落地的工作参考框架,助力快速上手AI训练相关工作。
一、认识AI模型
1.大语言模型(LLM)定义
底层原理:基于深度学习技术构建,能够理解并生成人类语言的AI系统,核心逻辑是“海量数据学习+深度学习框架”的结合。
主流大语言模型应用

2.多模态模型
核心定义
模态:信息处理的具体介质与传输手段(如文本、图像、音频、视频);
多模态:融合两种及以上信息类型的技术方法,通过跨模态协同提升任务性能、优化用户体验,实现更全面的数据分析。
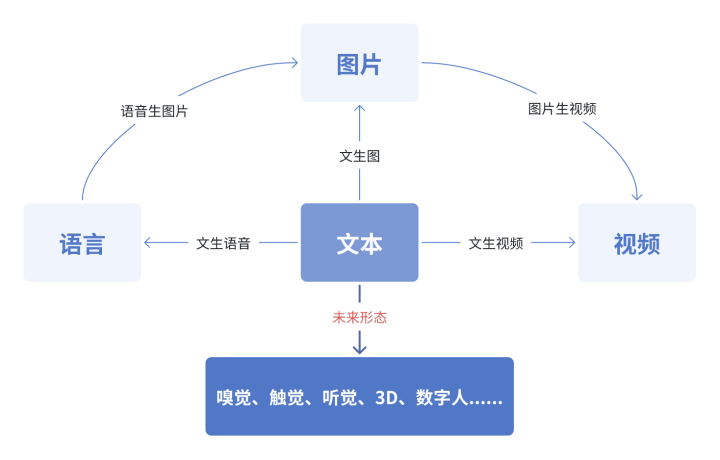
主流形态与未来方向
现有核心形态:文本→图像、文本→语音、文本→视频、图像→视频、语音→图像等;
未来发展方向:嗅觉、触觉、3D建模、数字人等跨维度模态融合。
主流图像生成产品
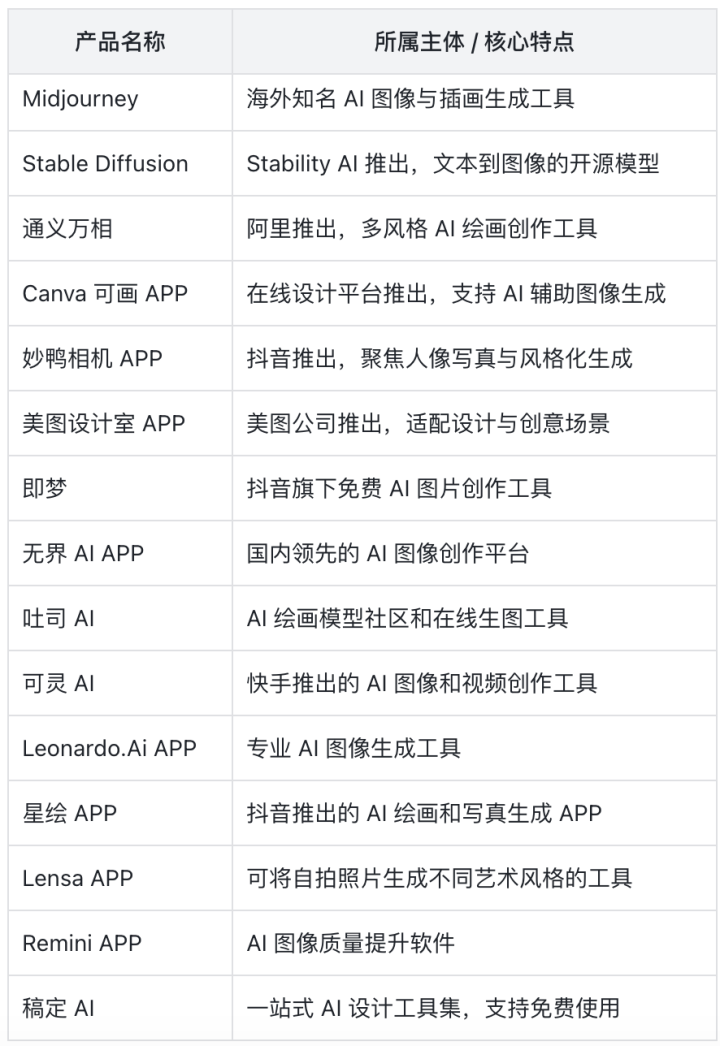
多模态模型核心应用场景
海报设计、广告产品图制作、医学解剖图/关节图生成、3D模型与IP角色设计、老照片修复与证件照优化、植物图/机械结构图绘制、图像融合创作等。
3.Agent
核心定义:基于大语言模型(LLM)构建的智能系统,具备自主感知环境、理解任务、决策规划与动作执行能力,可独立完成复杂目标任务。核心公式:Agent=LLM+工具调用。
通俗解读:Agent不仅能提供方案规划,还具备行动执行能力,可作为“智能代理”自主完成决策与落地(如自动规划行程、对接预订平台等)。
4.深度学习原理
底层技术基石:基于神经网络架构Transformer,核心是自注意力机制——模型处理文本时,可同时关注句子中所有词语的关联关系,而非仅局限于前后相邻词汇。
底层技术:神经网络架构Transformer;
自注意力机制(Self-Attention);
学习模式:以监督学习(微调阶段)为主,结合无监督预训练与参数动态调整机制。
5.模型训练过程
数据收集:构建高质量语料库
硬件需求:GPU等高性能计算设备支持
算法调优:优化损失函数、超参数调节
测试与迭代:持续验证模型性能并改进

中国发展AI的优势:人口多,用人成本低
二、AI训练师工作内容与职责
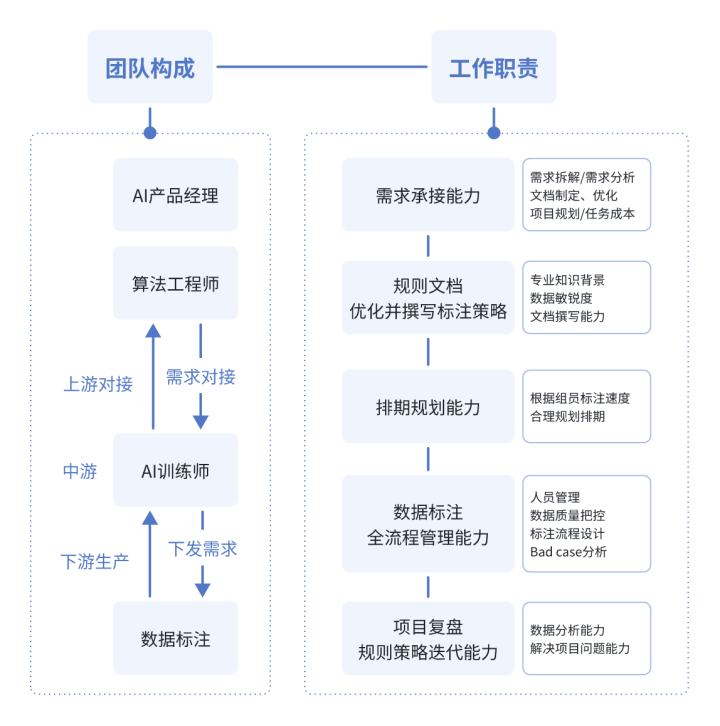
1.需求承接与规则制定
与产品经理或算法工程师沟通需求
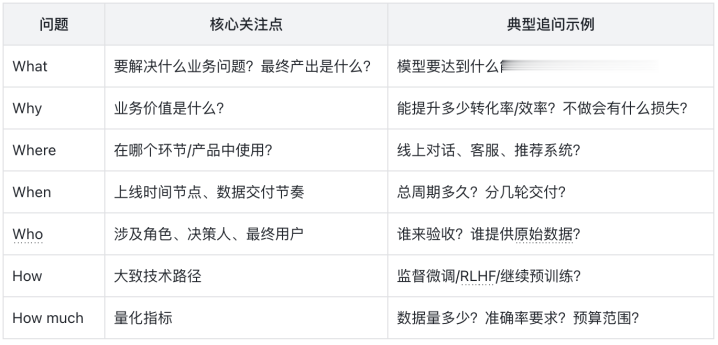
使用5W2H分析法明确任务目标(Who,What,When,Where,Why,How,Howmuch)
确定数据类型、数量、准确率要求
2.规则文档优化/数据标注与管理
制定详细标注规则(含示例说明)
小规模试标验证规则合理性
分配标注任务给具体人员
执行质检与验收流程,确保质量达标
3.团队管理与培训
培训标注人员掌握规则与工具使用
规划标注排期,保障进度可控
及时处理标注过程中的疑问与返工问题
需合理分配[标注人员]与[质检人员]数量
三、AI训练师工作流程
1.需求分析与规则制定
明确项目背景、业务痛点与核心目标;
分析数据来源、类型、量级及质量要求;
设定预期准确率、交付周期与验收标准;
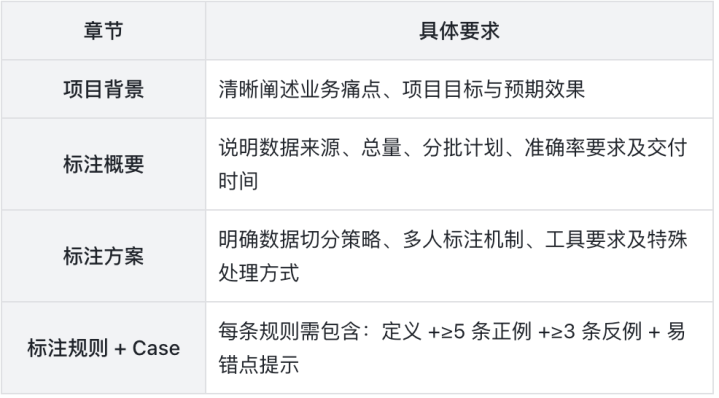
制定标注规则文档,经规则验证试标后定稿。
规则文档核心构成(缺一不可)

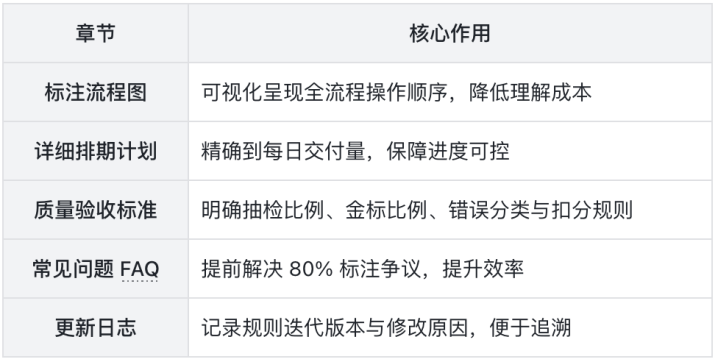
规则文档辅助内容(强烈建议)
2.标注与质检执行
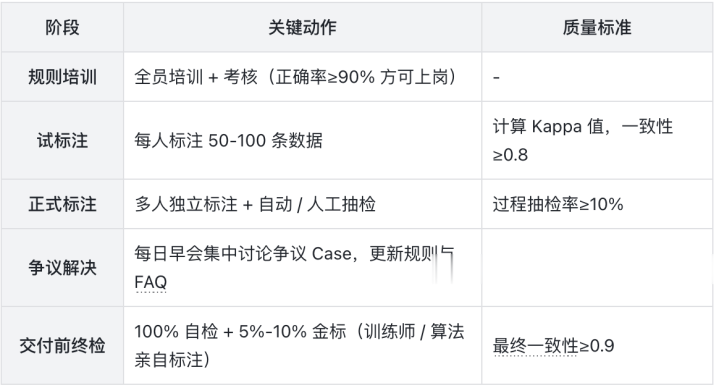
启动正式标注流程,同步开展过程监控;
建立多级质检机制(抽样检查、双人互检、金标复核);
每日处理标注疑问与争议Case,更新规则文档;
统计标注效率与准确率,及时调整资源分配。
标准执行节奏与质控要点
3.数据交付与模型训练
完成数据质量终检,剔除异常样本;
将清洗后的数据交付算法团队用于模型训练;
收集模型训练反馈,评估数据有效性;
完成项目验收,输出复盘报告。
举例:汽车厂商「用户购买意图标注」完整方案
项目基本信息
角色:AI训练师(协助AI产品经理承接标注需求与规则制定);
业务方:XX汽车厂商;
核心目标:训练大模型识别销售通话中用户的购买意图强度(强/中/弱),优化销售话术,提升成交率。
项目背景
基于汽车厂商真实销售通话记录,训练大模型具备“用户购买意图强度识别”能力,实时指导销售人员采取针对性沟通策略,最终提升整体成交转化效率。
2.标注概述
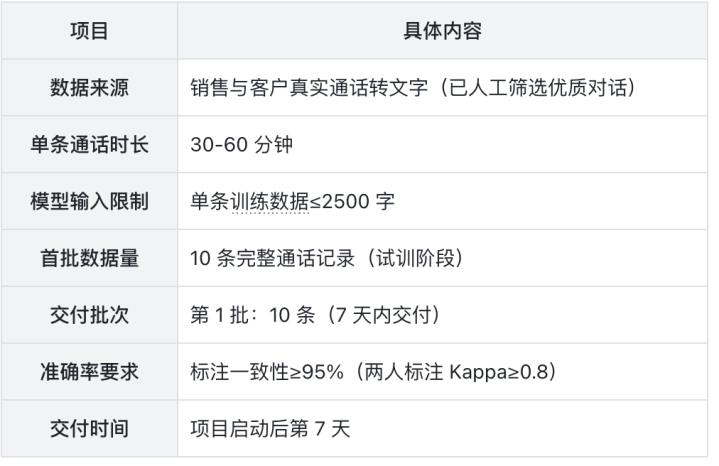
3.标注方案
长对话切分:将30-60分钟通话合理切分为≤2500字的片段,避免拆分完整语句;
标注粒度:仅对“用户语句”标注购买意图强度(强/中/弱);
质量保障:每条切分数据由2名标注员独立标注,分歧数据由AI训练师仲裁;
标注工具:推荐LabelStudio或内部专用标注平台。
4.详细标注规则
(1)对话切分规则(优先级排序)
优先在话题自然结束处切分;
其次在用户连续3句以上表述后的停顿处切分;
再次在语气助词(如“呃…”“嗯…”)或填充词后切分;
最后在长时间沉默处切分;
禁止在用户单句中间拆分。
(2)购买意图强度标注规则
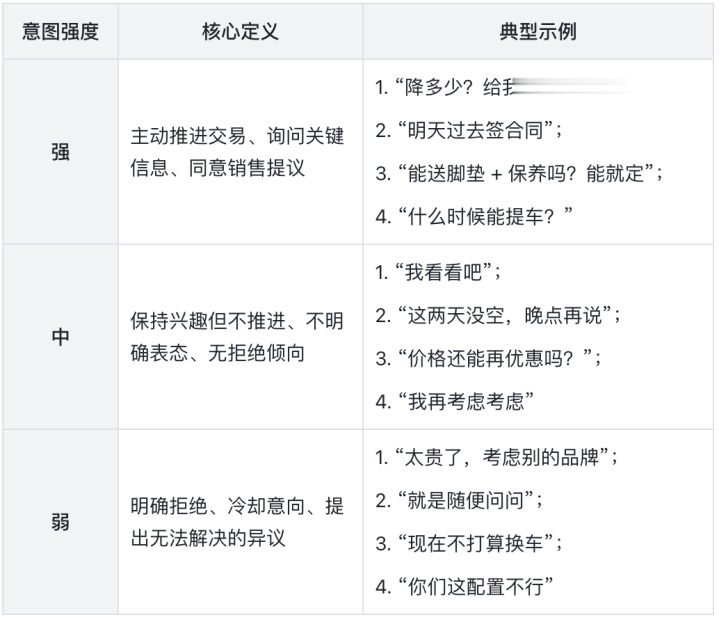
(3)特殊说明
仅标注用户语句,销售人员表述不标注;
用户无实质信息的短句(如“呃…”“嗯”)标注为“不标注/跳过”;
单句中同时出现强弱信号时,优先按更强信号标注。
5.质量标准
试标注阶段:前50条数据Kappa≥0.8方可进入正式标注;
正式标注抽检:抽检比例10%,及时整改不合格数据;
交付前金标:5%数据由AI训练师亲自标注,作为验收标准;
争议解决:每日早会集中讨论,规则当日迭代更新。
6.项目排期(7天版)
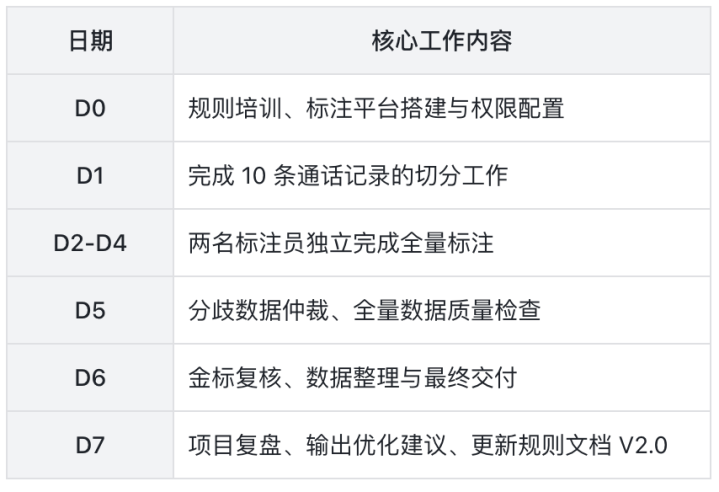
数据分析复盘核心内容(交付后3天内完成)
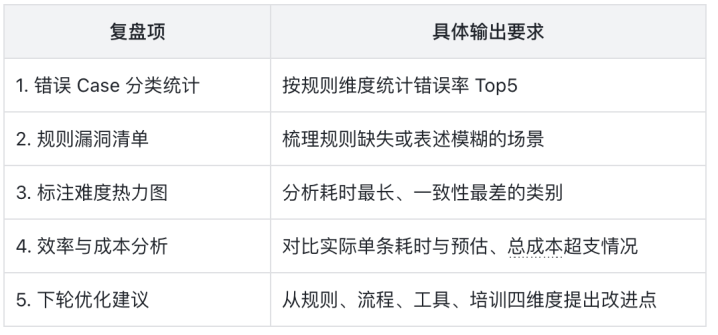
这样优化后的版本结构清晰、层次分明、表格化呈现关键信息,可直接作为AI训练师的SOP(标准操作流程)在团队内推广和培训使用。
至此,一份业务方看了就能立刻开工、标注员看了不会问东问西、算法看了能直接训练的完整标注方案就完成了。
后续若业务方追加数据量,只需在此文档基础上修改“标注概述”和“排期”即可快速复用。
四、外部资源利用
1.供应商与众包
供应商:依托固定团队优势,成本较低,准确率约70%;管理要点为签订保密协议,将抽检比例提升至30%-50%;
众包(大学生兼职):成本极低,时间灵活,但稳定性差、准确率更低;仅适用于简单标注任务,需强化过程监控。
2.基地与远程协作
跨地域团队管理:依托分公司(基地)人力,利用其低成本优势;
数据安全保障:建立权限控制、日志审计等安全机制,防范数据泄露;
效率提升措施:通过远程协作平台实现实时沟通,建立每日汇报与里程碑评审机制,确保进度与质量可控。
五、总结与实践原则
AI训练师的核心价值,在于搭建“业务需求”与“模型效果”之间的坚实桥梁——既要让数据标注有规可依、有质可查,也要让团队协作高效协同、持续优化。以下四大核心实践原则,是保障工作落地与效果闭环的关键:
规则先行:标注工作启动前,必须完成规则设计与规则验证试标,明确“定义+正例+反例+易错点”,从源头避免无规可依导致的返工与争议;
质量优先:建立“培训–试标–抽检–仲裁–复盘”多级质检机制,通过Kappa值校验、金标复核等手段,杜绝低质数据污染模型,守住数据质量底线;
动态优化:不以“交付”为终点,而是依据模型训练反馈、标注过程中的BadCase,持续迭代标注规则与流程,让数据质量随业务需求同步升级;
协同高效:借助数字化协作工具(如LabelStudio、飞书文档)打通跨地域、跨角色协作壁垒,通过明确排期、每日同步等机制,平衡效率与质量。
文档优化总结
核心修正:明确“规则验证试标(验证规则合理性)”与“标注员上岗试标(考核标注员能力)”的本质区别,补充深度学习“无监督预训练+监督微调”的完整学习模式,避免概念混淆;
结构优化:梳理重复工具罗列与表述,统一“试标”“抽检比例”等术语,通过表格、分点突出核心指标与流程节点,提升阅读效率;
实用提升:强化汽车厂商标注案例的可操作性,细化规则文档的“四核心+五辅助”构成,让新手可直接套用模板、团队可快速落地执行;
知识保障:所有核心概念、流程逻辑、量化指标均贴合行业实践,无技术偏差与逻辑漏洞,既适用于AI训练师入门学习,也可作为团队内部标准化工作手册长期使用。
AI技术的落地,终究离不开高质量数据的支撑。希望本文能为AI训练师、产品经理、算法从业者提供清晰的工作指引,让数据标注从“零散执行”走向“标准化闭环”,真正为模型效果赋能,助力AI技术在各行业的深度落地。